
Every Legal AI Vendor Wants to Be Your Operating System. What's Your Exit Plan?
The $11 billion bet that law firms won't own their own data.

Harvey just raised $200 million at an $11 billion valuation. Legora closed a $550 million round at $5.55 billion. Thomson Reuters paid $650 million for Casetext. Microsoft built Copilot into the M365 stack most firms already run on. Oh, and of course Anthropic just dropped Claude inside Microsoft Word.
These companies are not building tools. They are building operating systems. And every one of them wants to be the layer your firm can't turn off.
The pitch
Gabe Pereyra, Harvey's co-founder, published a piece last week called "Legal is Next." The thesis: Harvey has built an internal agent called Spectre that handles work autonomously, triggered not by humans but by the system itself. The implication: this architecture will soon run inside law firms. Artificial Lawyer called it a potential "law firm world model."
Pereyra frames it as liberation. Agents replace the base of the pyramid. Associates stop doing throughput work. Partners focus on judgment. The firm reorganizes around what he calls "a surplus of intelligence bottlenecked by judgment."
It's a good phrase. It's also a pitch from a company that grew from $100 million to $190 million in ARR in five months, now serves over 100,000 lawyers across 1,300 organizations, and needs to justify an $11 billion valuation to Sequoia, Andreessen Horowitz, and every other investor at the table.
What they're actually capturing
Here's what most legal teams miss about these platforms.
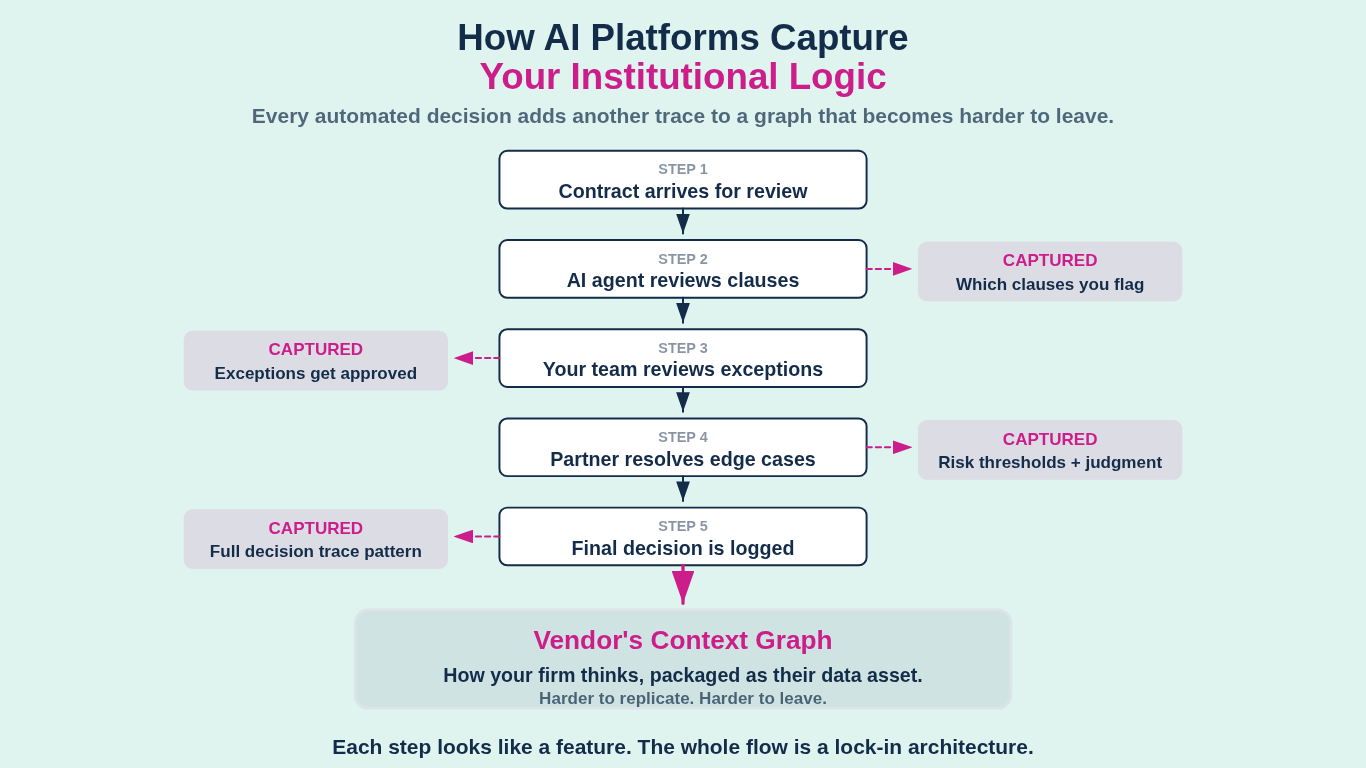
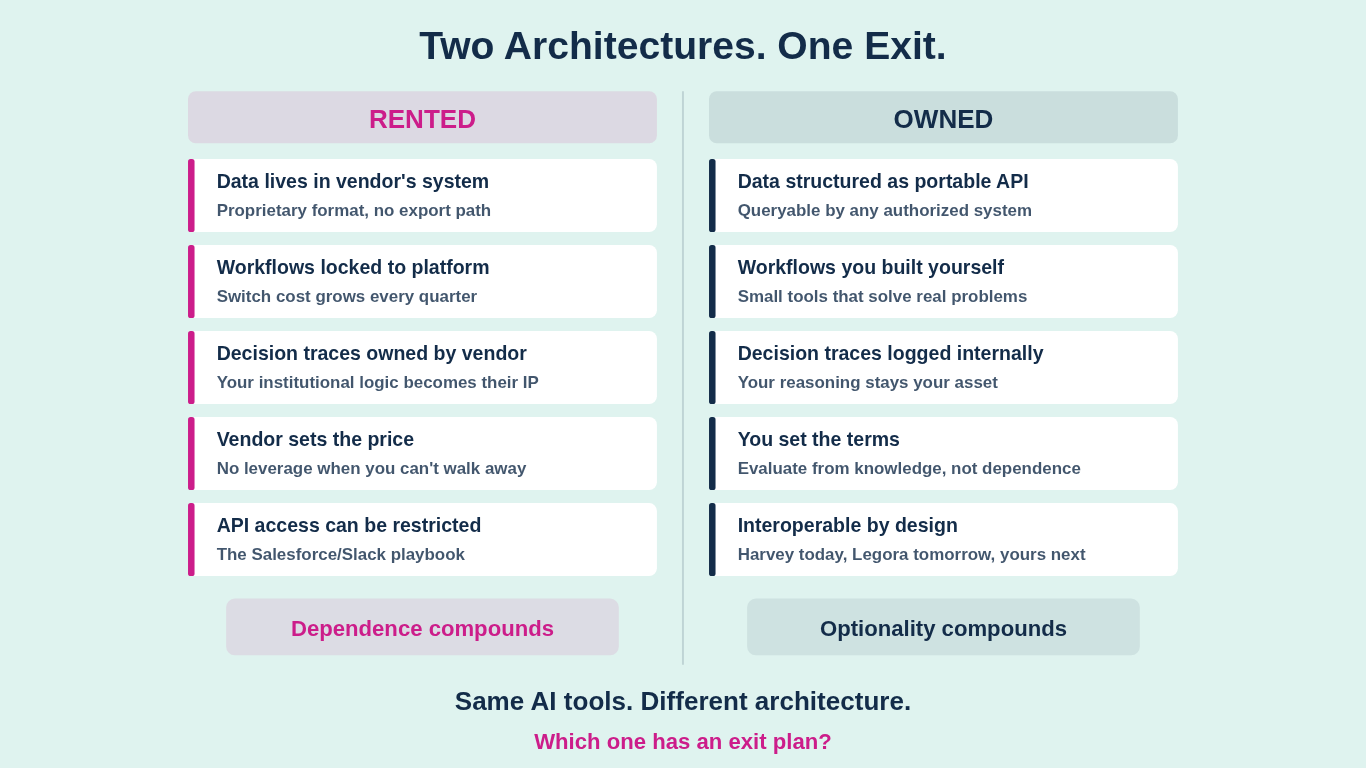
The obvious concern is data. Your documents, your research, your matter files. That matters, but it's not the real play. The real play is what Foundation Capital's Jaya Gupta calls "decision traces": the record of how your firm actually makes decisions.
When an agent handles contract review, it doesn't just process the document. It captures which clauses your team flags, what exceptions get approved, which risk thresholds trigger escalation, and how partners resolve edge cases. That reasoning, the institutional logic connecting data to action, was never treated as data before. Now it is. And whoever's platform captures it owns something far more valuable than your files.
Gupta's argument is direct: "SaaS incumbents can add AI to their data, but they can't capture what they never see." The companies sitting in the execution path, Harvey, Legora, whoever processes your actual work, see the full decision context. The inputs gathered. The policies evaluated. The exceptions granted. Every automated decision adds another trace to a graph that becomes harder to replicate and harder to leave.
These platforms capture how your firm thinks.
Why "check your contract" is not a strategy
Most advice about vendor risk boils down to "negotiate better terms" or "read the contract carefully." That's not wrong. It's just insufficient. It's like telling someone to read the nutrition label while the food supply chain is being redesigned around them.
The structural issue isn't contract language. It's architectural. If your workflows, your decision patterns, and your institutional knowledge all live inside a vendor's system, your contract terms are a guardrail on a road you don't own.
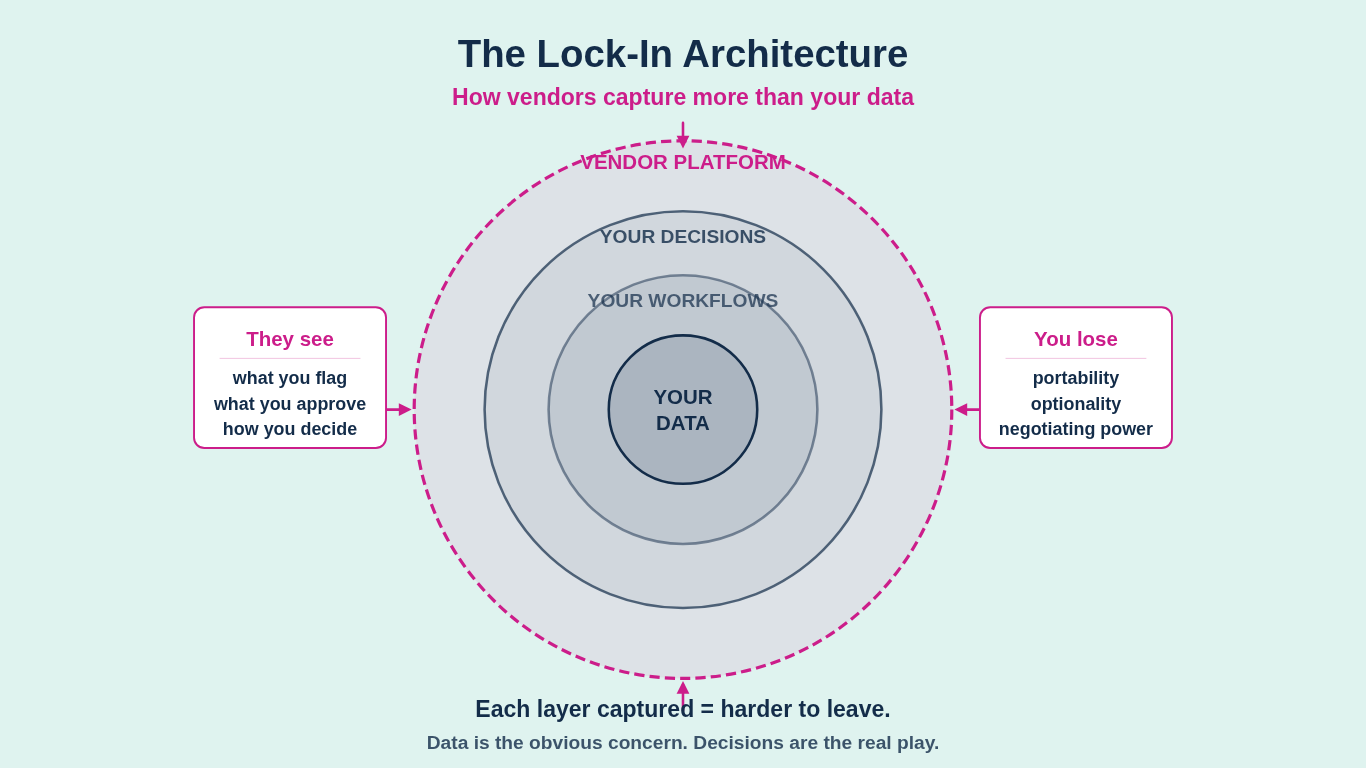
And the platforms know it. Salesforce already restricted AI competitors' access to Slack data. Foundation Capital predicts more of the same: "more limits on API usage, more restrictive terms, and more integration hurdles." The access gets tighter, not looser, as the vendor's position strengthens.
Meanwhile, 69% of legal professionals now use generative AI tools at work, more than double from last year. But 54% of law firms offer no AI training and 43% have no AI governance policy. That's mass adoption without the architectural literacy to understand what's being adopted or what's being surrendered.
A real path forward
Here's to actually do. Not in theory. In practice, this quarter.
Build small tools that solve real problems now. You don't need to replace Harvey. You need to stop being helpless without it. A microsaas that automates your NDA intake, a small app that routes contract requests based on your own logic, a simple tool that formats your research memos the way your partners actually want them. These aren't products. They're proof that your firm can build its own workflow logic rather than renting someone else's. Every small build compounds your team's understanding of how software actually works. That understanding is what lets you evaluate vendors from a position of knowledge rather than dependence.
Make purchasing decisions architecturally, not feature-by-feature. Stop comparing AI vendors on what they can do and start evaluating them on how they connect to what you already own. The questions that matter: Does this tool work with my data where it already lives, or does it require me to move everything into its system? Can I pipe outputs from this tool into other tools via API, or does it only work inside its own walls? If I stop paying, what do I keep? Engineers call this evaluating "interoperability and portability." Legal teams should call it due diligence.
Treat your data as an API, not a filing cabinet. This is the mindset shift that changes everything. Your matter data, your contract corpus, your research memos, your decision history: this isn't static content sitting in folders. It's an asset that should be queryable by any system you authorize. When your data is structured and accessible via API, you can plug it into Harvey today, switch to Legora tomorrow, and build your own internal tool next quarter. When your data lives inside a vendor's proprietary format with no export path, you've handed over the keys. The firms that structure their data as a portable, machine-readable layer will have options. Everyone else will have a vendor they can't leave.
One giant caveat here. Anyone that has spent anytime inside a law firm or legal department knows that your data is not clean. Its all over the place, and often living inside some lawyer or legal ops professional’s brain. So to get the data API layer right, you have to go back to basics and start building data the right way.
Own your decision traces. This is the new frontier. If you're using an AI platform that captures how your firm makes decisions, you need to know where that record lives. Can you export it? Is it in a format you can use elsewhere? Or does it exist only inside the vendor's system, making your institutional logic their proprietary data? The firms that log their own decision patterns, even in simple internal systems, keep the one asset that's hardest to rebuild from scratch.
The real training deficit
Pereyra says "intelligence replaces hierarchy." Maybe. But intelligence supplied by a single vendor, trained on your data, priced at their discretion, and embedded so deeply that extraction would take years of re-engineering is not independence. It's a different kind of hierarchy with a different owner.
The vendors racing to $11 billion valuations are building something real. The technology works. I'm not arguing against using it. I'm arguing against using it blindly.
The teams that learn how software architecture works, how data flows, how APIs connect systems, and how vendor lock-in actually operates will make better decisions than the teams chasing the most impressive demo. That has always been true of infrastructure decisions. AI is not different.
The gap between the firms that understand these systems and the firms that just buy them widens every quarter. That's a compounding problem. And nobody is going to close it for you.