
The Six Things That Actually Compound (When Every Week Brings a New AI Tool)
Where to start when the feed is full of "must-try this weekend."

Every week another framework, another plugin, another agent pattern, another demo with a thousand likes. The feed is full of "must-try this weekend." Most of it never compounds. You install three tools, try one, forget the rest, and Monday morning the model has lost the context you spent Sunday building.
I run this gauntlet too. A newsletter, podcast, consulting. Plugins to build, training to deliver, operations to improve across my businesses. This is what I do for a living and its still a lot to learn this stuff, teach it, and build with it. My job is to cut through the noise so you can stay on the foundations that compound. This piece is one of those cuts. I do all my work inside coding agents now. Claude Code, Codex, Open Code, etc. This works for marketing, legal, sales, coding and more. Take my ideas, apply them to your workflow. Master these six and your skills compound.
Harness | Memory | Plugins | Subagents | Voice | Verification

How most builders handle it
Two default moves. The first is the demo chase: install whatever launched this week, try it once, never come back. The second is the freeze: wait six months until the noise dies down, by which point the people who started earlier are two compounding cycles ahead. Both leave you in the same place. Outside the work, watching.
Why it breaks
The problem is not tool selection. It is that almost no one has the foundations underneath. You can install forty plugins and still re-type your brief every session, lose your memory between conversations, watch a model drift off-task on a vague request, and accept its first answer because you have no way to check it. The tools are not the leverage. The harness, memory, and discipline around them are what give you the advantage.
A different approach
I stopped chasing features two years ago. I picked six foundations and rebuilt them every time something changed. New model, new harness pattern, new plugin format. I update the six, not the surface. The six are the part that compound. Anything on top is interchangeable.
Here is the six pieces I use in my own stack that have helped me, help you. Harness, Memory, Plugins, Subagents, Atomic Scope, and a Verification loop.
1. Good harness
The harness is the contract you give the model before any task. It tells the model what kind of work this is, what is in scope, what is out of scope, what "done" looks like, what to do when blocked, and what to never touch.
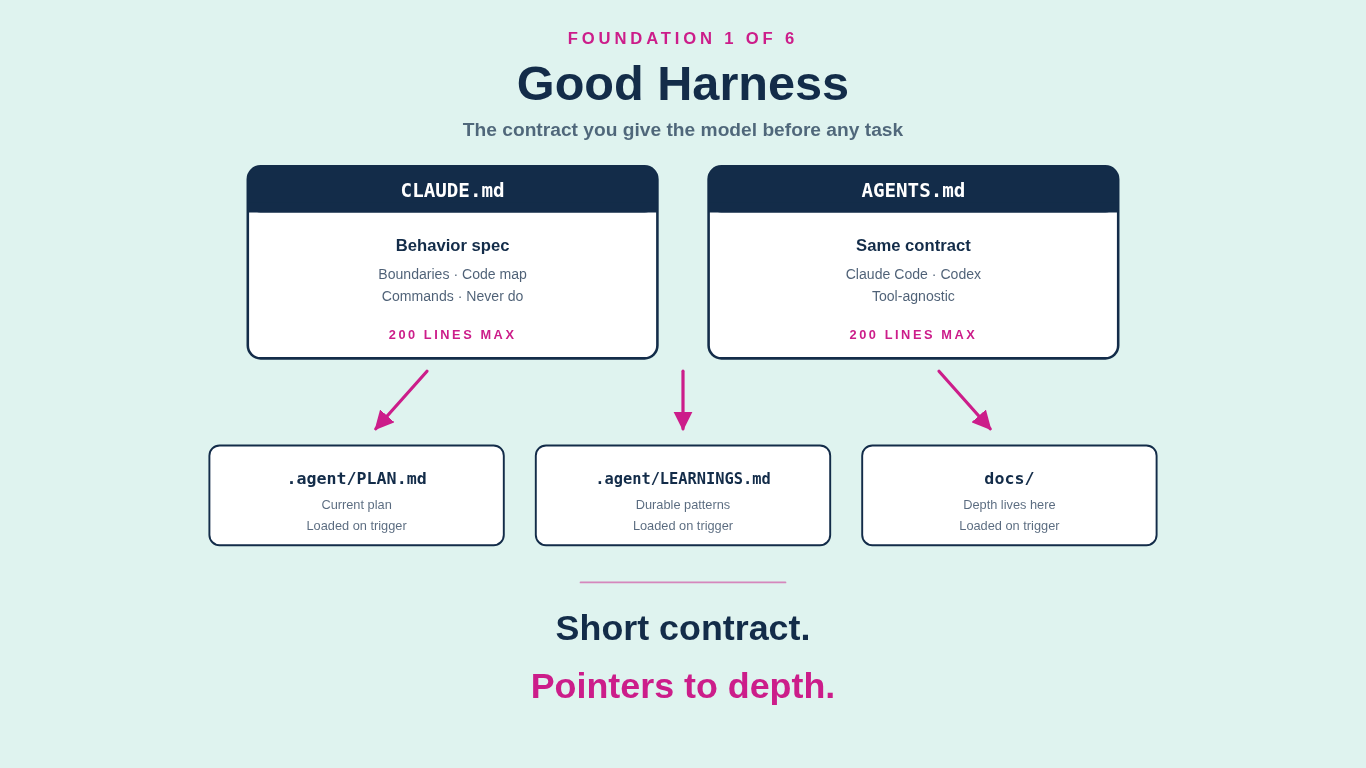
For me, the harness lives in two paired files at the root of every repo: `CLAUDE.md` for when I am working in Claude Code, and `AGENTS.md` for when I am working in Codex or any other agent that reads the AGENTS convention. My agent starter pack writes the same contract to both, because the tool of the month should never break the workflow. The contract is the same. The reader changes.
The detail that took me longest to get right: both files should be short. 200 lines at most. The job of `CLAUDE.md` and `AGENTS.md` is not to hold every fact about the project. The job is to define the startup contract and point at the documents that actually carry the detail. Boundaries first. Code map second. Commands third. "Ask first" and "never do" lists at the bottom. Everything else lives in `.agent/PLAN.md`, `.agent/HANDOFF.md`, `.agent/LEARNINGS.md`, `docs/`, or wherever else the project keeps depth, and the model loads those only when the request triggers them.
That pointer-driven structure is what keeps the token bill honest and the model focused. Every paragraph you stuff into the startup contract is a tax on every single session, whether or not that session needs the information. Most sessions do not. Move depth out of the contract and into the documents it points to, and the model reads exactly what it needs and nothing more. The starter pack has more of these small moves baked in.
The mistake most people make is treating `CLAUDE.md` and `AGENTS.md` like documentation: long, polite descriptions of the project. That is not what they are. They are behavior specs. Short. Imperative. Pointer-driven. If your harness reads like a README, rewrite it as a contract.
2. Good memory
Memory is the state the model can read across sessions. It is not what the vendor stores inside a chat history. It is what you keep in files, in the same repo as the work, under your control.
My memory layer is plain markdown. Each repo has `.claude/history.md` for session summaries: date, files changed, key decisions, current state, next steps. Each repo has `.agent/LEARNINGS.md` for durable patterns the model should apply next time. Global memory lives under `~/.claude/projects/<repo>/memory/` with one file per fact, indexed in a `MEMORY.md` table of contents. The model reads these on startup when triggered by the request. The model writes to them when it learns something worth keeping.
You can do this manually at the end of your session, or have the coding agent add key information automatically. Either way, when you come back to it later, you aren’t starting from zero or forcing the agent to review everything.
Two things matter about this setup. First, the format is greppable. I can search across every session I have ever run on a project and find the moment I made a decision. Second, the format is portable. When a new model lands, when a new harness ships, when I switch tools entirely, the memory comes with me. None of it is locked inside a vendor's storage.
Closed memory inside a vendor product is rented ground. The day the vendor changes pricing, deprecates a feature, or shifts model access, your accumulated state goes with it. You start over. Builders do not start over. Builders keep their memory in files they control.

3. Good plugins
Plugins are the small, named, repeatable units of work a model can run without you re-explaining the instructions. A skill that knows how to draft a Substack article in your voice. A skill that knows how to build out a deposition witness kit. A skill that knows how to run your matter intake system. Each plugin is a folder of markdown and config that the model loads on demand.
The wrong question is "which plugins should I install." The right question is "which tasks do I do weekly that I want a model to never forget how to do." Answer that, and the plugins almost write themselves.
For my coding work, the stack is small. My own PossibLaw-Plugins for content drafting, design grilling, and triage. The `superpowers` plugin from Anthropic for TDD discipline, brainstorming, debugging, and the cross-cutting workflows I want enforced regardless of project. A handful of single-purpose plugins for specific clients. Five total, give or take. Not forty.
The other mistake to avoid is installing a plugin and never editing it. Plugins are scaffolds, not finished products. The first thing I do with any plugin I install is read the SKILL files, find the one place it does not match how I actually work, and patch it. That is the difference between a consumer of plugins and an author of them.

4. Agents to manage context
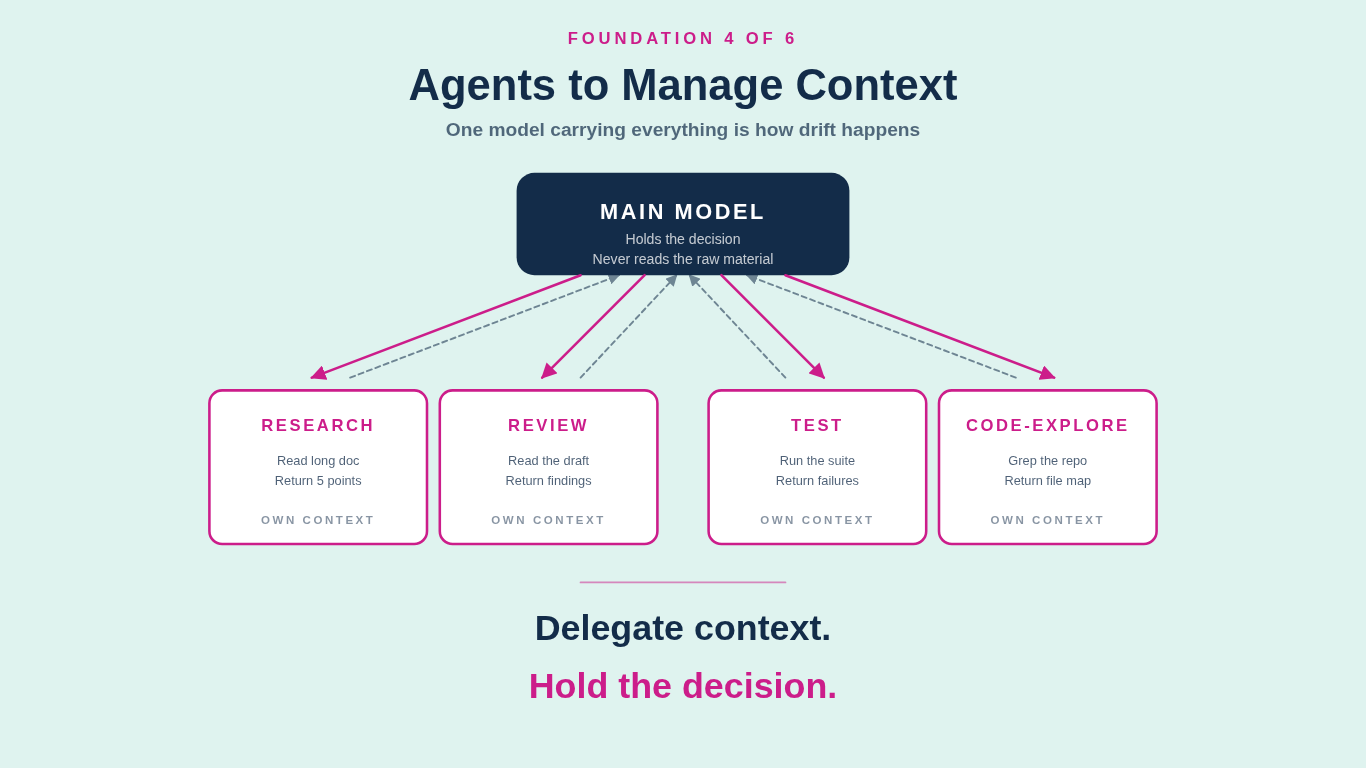
A subagent is a separate model run inside a larger task. Its own context window, its own tools, its own system prompt, its own short brief from the main model. It does one thing, returns a summary, and exits. The main model never sees the raw material the subagent read.
This sounds like a small optimization. It is the difference between a session that holds together and a session that decays. One model carrying every concern is how drift happens. Research blurs into drafting, drafting blurs into review, the context window fills up with old tool output, the model starts compressing earlier turns, and forty turns in the thread is lost. You feel it as the model getting "dumber." It is not. The context is exhausted.
The fix is delegation. I use subagents constantly. A research agent reads a long external document and returns a one-page brief. A code-exploration agent greps through a repo for every reference to a symbol and returns a list of file paths and line numbers. An editorial reviewer reads a draft against the brand rubric and returns severity-rated findings. A test-runner agent runs the test suite, parses the failures, and reports which ones are real versus flaky. Each one gets a clean context, does its job, and disappears. The main model stays sharp because it never had to hold the full source material itself.
Parallel agents are the second move worth learning. When two pieces of work are independent, run them at the same time in different subagents. I cut a research-heavy task from twenty minutes to three this way last week. Independent work in parallel is free latency reduction.
5. The voice unlock
The hidden friction in large projects is the endless typing and it is the reason most people abandon good context engineering and prompt hygiene. The fix is to take typing out of the bottleneck.
Voice is the biggest unlock I have added to my workflow in the last year. I dictate almost every prompt during a working session. The built-in macOS dictation will get you started. The tool I actually use is Wispr Flow, which transcribes faster and more accurately and adds the move that changes the math: snippets. A snippet is a short trigger that expands into a reusable block of text. I have snippets for the prompts I run constantly. A few words paste in the brand voice file. Another loads the editorial rubric. Another pastes the link to the project brief I always reference. Another fires off "treat this as TDD, write the failing test first, then implement, then verify."
Every time I notice myself typing or speaking the same context twice, I make it a snippet. After a month, the slow part of the loop is not me anymore. It is the model. That is the right place for the bottleneck to live.

6. A verification loop
This is the one most vibe coders skip, and it is the one that decides whether the other five compound errors or compound leverage.
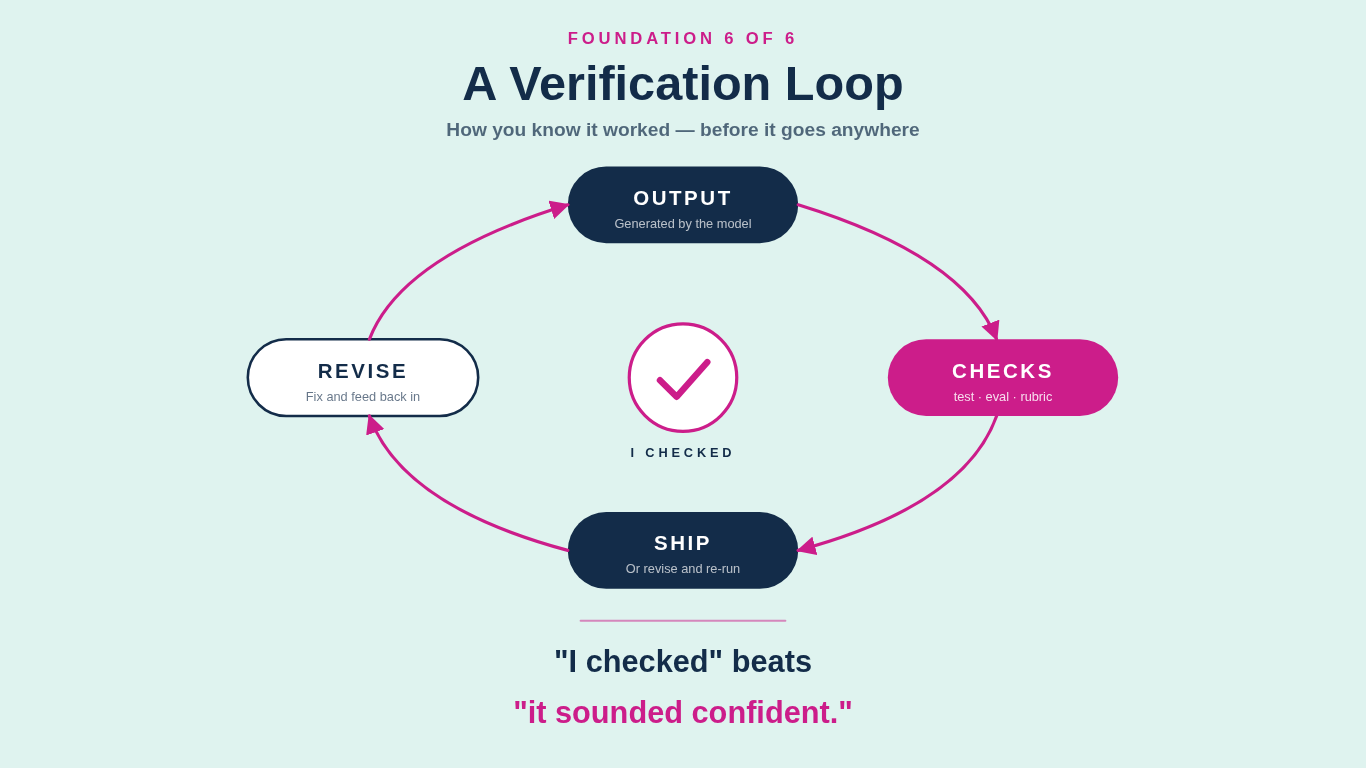
Verification is how you know it worked. A test. An eval. A rubric. A known-good input run through the new system to see if the output matches what it should. A second model checking the first model's work. A diff against the previous version. A human spot-check on the riskiest output. The form varies. The discipline is the same: you do not trust the output until you have checked it.
For legal work the stakes make this obvious. A confidently wrong citation is a Rule 11 problem, not a productivity gain. A confidently wrong privilege call is a malpractice problem. A confidently wrong redline that drops a key carveout is a deal problem. Everything an AI produces in a legal workflow needs a verification step before it goes anywhere a partner, a client, or a regulator can see it.
For everyone else the stakes are still real. Code that looks fine and ships without tests breaks in production two weeks later, usually at 11 p.m. on a Friday. Content that looks fine and ships without an editorial pass goes out with the brand voice slightly off and a fact slightly wrong, and you do not catch it until the third reply on LinkedIn. "I checked" is the discipline that separates builders from passengers.
The cheapest verification loop is a one-page rubric per workflow. For my Substack drafting, the rubric is the four-question self-edit checklist plus the brand voice file. For my plugin work, the rubric is "did the validator pass, and does the README example actually run." For my client work, the rubric is matter-specific and lives in the harness. None of these are fancy. All of them get run every time.
The ReCode
The question is not which new tool to learn this week. It is whether you have the foundations that let any tool compound.
Pick one of the six. Get it right by Friday. Do the next one the week after. By the time the next AI announcement lands, you will read it as a builder reading a spec, not as a tourist reading a brochure.
That is what I am here for. Cutting through the noise so you can build is my job. This newsletter, the podcast, the training, the plugins, all of it points at the same outcome: foundations that compound, week after week, regardless of what ships next. I can’t wait to see what you go build.