
You Never Audited the Associate's Brain
Legal has always trusted intelligence it can't inspect. The newest AI models just make that explicit.

A senior partner hands back a research memo with three redlines and a signature. She has no idea which neurons fired in the associate's head while he wrote it, what half-formed theories he discarded at midnight, or why the controlling case surfaced in his memory when it did. She read the memo. She judged the memo.
Legal has always trusted intelligence it can't inspect. It just never admitted it.
That habit is about to be tested, because the newest AI models now do their best work in ways nobody can fully explain, including the people who built them.

The black box got smarter
This week Anthropic released Claude Fable 5, the first publicly available model from its new Mythos class, a tier that sits above the Opus line most legal teams have been piloting. On some benchmarks it scores more than 10 percent higher than Opus 4.8, a model Anthropic shipped only weeks earlier. The ceiling keeps moving, and it's moving fast.
What hasn't moved nearly as fast is anyone's ability to explain what happens inside these systems. Anthropic's own CEO, Dario Amodei, put it plainly in his essay The Urgency of Interpretability: "People outside the field are often surprised and alarmed to learn that we do not understand how our own AI creations work."
To be clear about where I stand: that research matters, and I want it to succeed. Amodei isn't shrugging at the black box. He's calling for an MRI for AI, because every gain in interpretability is a gain in our ability to steer these systems, and steering is exactly what high-stakes professions need. Keep rooting for that work.
But you don't get to wait for it. The models are in your inbox now. Your legal teams are using them. The practical question in front of every legal team isn't whether researchers will eventually open the box. It's how to evaluate work product from a system you can't fully see into, today.
The honest answer is: the same way you've always evaluated work product from a system you can't see into. By the output.
We already run on outcome evaluation
The profession's machinery for trusting humans is almost entirely outcome-based. Bar exams test output. Writing samples are output. The first years of an associate's career are one long output evaluation: memos redlined, drafts rewritten, judgment reviewed. Nobody administers a brain scan. Competence is inferred from work product, over time, against a standard.
The profession's own ethics guidance follows the same logic for AI. ABA Formal Opinion 512, the ABA's first comprehensive guidance on generative AI, says lawyers "need not become GAI experts." The duty is a reasonable understanding of the tool's capabilities and limitations, paired with independent verification of what it produces. Read that carefully. The obligation attaches to the output and to your judgment about the output, not to mechanism mastery. You can be fully competent and fully ethical using a tool whose internals you can't trace, as long as you rigorously evaluate what it hands you.
That's not a loophole. That's how supervision has always worked.
What the fifteen-step version looks like
Here's the kind of system legal ops teams have been building for years, and building well.
A contract comes in for intake. The deterministic version:
1. A watch folder or email listener detects the file
2. A file-type check routes it: native PDF one way, scanned image another
3. An OCR engine converts scans to text
4. A parser reconstructs the document structure
5. Extraction rules pull party names, dates, renewal terms, governing law
6. Validation logic checks the pulls against expected patterns
7. Error handling catches failures at each joint and routes them to a human queue
8. A converter writes results into the CLM or matter system
9. Logging records every step for the audit trail
Every connection between those boxes was designed by someone, built by someone, and is maintained by someone. When the OCR vendor updates its API, someone fixes step three. When a new contract template breaks the extraction rules, someone patches step five.
There is real value here, and I'm not pretending otherwise. Anthropic's own engineering guide, Building Effective Agents, draws exactly this line: deterministic workflows buy you predictability, consistency, traceability, and cost control on well-defined tasks, and the guide explicitly recommends "finding the simplest solution possible, and only increasing complexity when needed." A pipeline like this runs at pennies per document. You can show an auditor what happened at every step. For a fixed, high-volume task, it's a beautiful machine.
It's also expensive in a currency that never shows up on the invoice: an engineer to build it, a legal ops person to own it, and a permanent maintenance obligation that starts the day it ships.
What the one-sentence version looks like
The same task, handed to a frontier model:
"Here are today's incoming contracts. Extract the parties, effective and renewal dates, and governing law from each, flag anything unusual against our playbook, and return a summary table plus a structured file for the contract system."
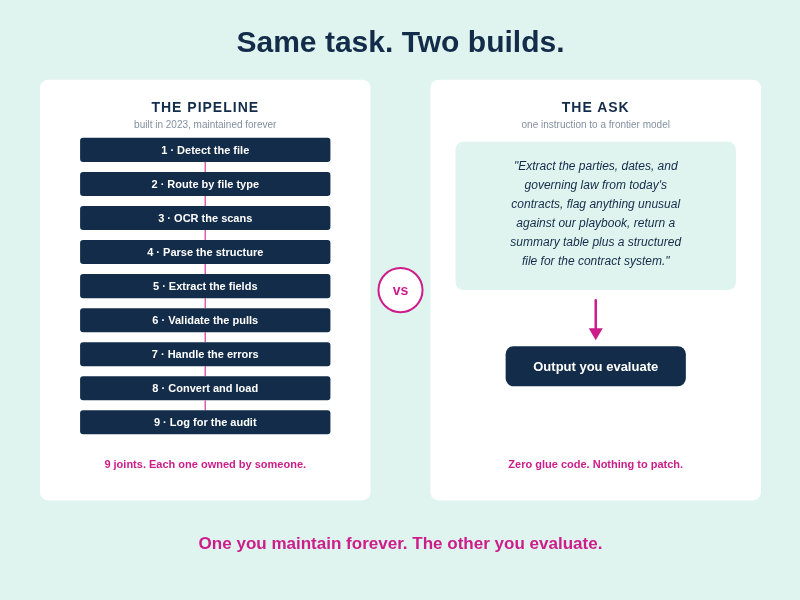
That's the whole build. No parser selection, no OCR integration, no extraction rules, no glue code. A model like Fable 5 reads the scanned PDF, handles the messy formatting, applies the playbook, and produces the output. When a strange new contract format shows up, there's no step five to patch. The instruction doesn't change.
What you give up is exactly what the pipeline gave you. There's no OCR step to point at, because there isn't one you can see. Per-document cost stops being a deterministic constant: Fable 5 runs $10 per million input tokens and $50 per million output tokens, roughly double Opus pricing. You traded step-level control for outcome-level capability.
So here's the question, and I mean it as a genuinely open one: is that trade worth it?
The dollars are half of it. The other half is understanding. With the pipeline, you understood every joint, and that understanding was itself an asset. You could explain the system, debug it, defend it. With the model, you understand the inputs, the instruction, and the output. The middle belongs to the machine. Whether that's a price worth paying depends on the task, the stakes, the volume, and what you're actually optimizing for. I'm not handing you an answer. I'm telling you the question has arrived, and the teams that start reasoning about it now will be far better positioned than the teams still stitching fourteen workflows together by reflex.
The objection that deserves a real answer
The instinct resisting all of this is a good instinct. Lawyers don't trust black boxes. Audit trails exist because memories are short and disputes are long. "The model said so" will never survive a malpractice deposition.
All true. And none of it is an argument for fifteen connected steps. It's an argument for rigorous output evaluation, which is a different discipline than process surveillance.
When work product is wrong, it's wrong whether it came from a beautiful pipeline or a single model call. Opinion 512's verification duty doesn't ask where the draft came from. It asks whether you checked it before relying on it. So build golden test sets. Define pass and fail before you run the task, not after. Sample outputs against a rubric the way a partner samples an associate's work. Keep the inputs, the instruction, and the output as your record. That is an audit trail. It's just drawn around the work instead of through the machine's internals.
And where the criterion truly is per-unit cost at massive volume, or a regulator demands step-level traceability, or the task will never change shape, the deterministic pipeline is still the right call. Anthropic says the same thing about its own models.
Two desks, one mandate
A GC gives two team leads the same assignment: get NDA intake under control by end of quarter.
The first lead does what worked in 2023. Scopes a pipeline, gets a vendor quote for the OCR integration, borrows an engineer for six sprints, builds the nine steps. It ships in week eleven and runs cheap. Two weeks later a counterparty starts sending NDAs as photographed pages pasted into Word files, and step three begins failing silently. The engineer is on another project now. The queue backs up while a ticket waits.
The second lead spends the first week somewhere else entirely: writing down what a correct intake looks like. Twenty sample NDAs, a rubric, pass and fail criteria for every field. Then one carefully written instruction to a frontier model. The build takes an afternoon. The photographed-pages curveball lands the same week, and the model just reads them, because reading messy documents is what it does. The lead's review time goes where the rubric says the risk actually lives.
By end of quarter, both desks have a working system. One lead owns a machine. The other owns an evaluation discipline, and the discipline transfers to the next model, the next task, the next quarter.
Match the tool to the task
You wouldn't staff a bet-the-company appellate brief with a paralegal, and you wouldn't bill a senior partner's rate for photocopying exhibits. Matching the resource to the task is the oldest staffing instinct in legal.
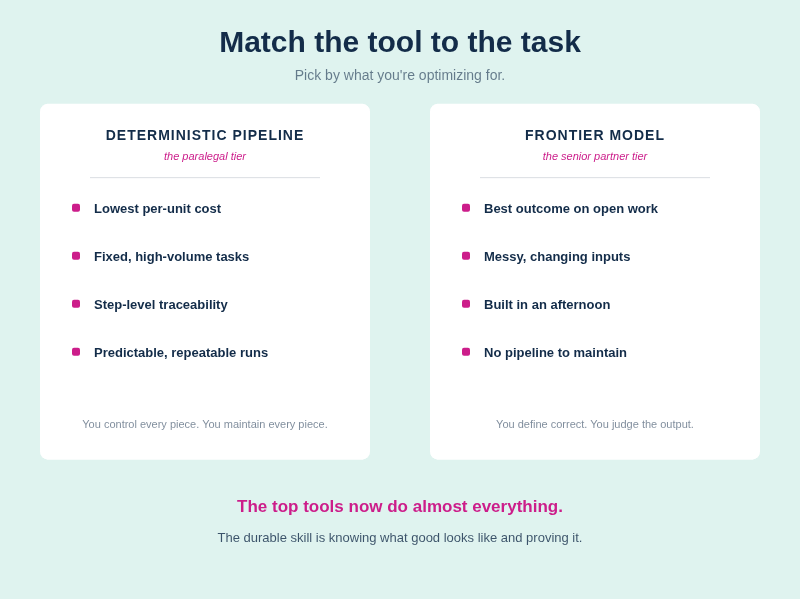
The models slot into that same instinct, with one update that changes the math: the top tools can now do almost everything. The paralegal-tier option and the senior-partner-tier option sit in the same dropdown. Use the small, cheap, deterministic option when cost, volume, or mandated traceability is what you're optimizing for. Reach for the frontier model when the criterion is best outcome. Just stop defaulting to fifteen connected steps because that's what last year's playbook said to build.
So What do you do?
The durable skill in all of this isn't pipeline construction, and it isn't prompt tricks. It's knowing what good looks like and being able to prove it. The lawyers who can define correct, build the test, and judge the output will be comfortable with every model that ships from here, including the ones nobody can explain yet. That was always the job. The associate's brain was never the thing you were evaluating.
Memoria brevis, odium longum